Text-to-speech (TTS) synthesis has been an area of research for several decades now. As the name suggests, text serves as the input and a speech waveform is produced as output. In the last few years the use of TTS systems in real-world applications has become ubiquitous. You just have to mention “Siri” or “Alexa” and people know exactly what you are talking about. Virtual agents such as Siri or robots can interact with people about various topics such as the weather, traffic, or how best to prepare a turkey. Other TTS applications involve GPS navigation in cars, or web/document reading for accessibility, in education or second language learning.
There are many companies offering TTS voices these days, many of them using machine learning engineers to train the neural networks, but I hope this post will give some insight into some of the underlying knowledge about linguistics, phonetics, prosody that can help improve the quality of the synthesis. In this blog post, I will give a general overview of the TTS process. I intend to write more posts in the future highlighting various aspects in more detail and talking about other important topics such as evaluation and ethics.
Speech
Human speech production is a complex process. To produce speech involves planning in the brain of what someone is going to say, air moving from the lungs out through the vocal or nasal tract, muscles in the vocal tract and lips to change the shape to control the type of sounds that are produced and the pitch and loudness of the speech.
Speech consists of sequences of speech sounds, also called phones. While a language has a limited phone inventory, there can be infinite variations in the phones as they are influenced by coarticulation from surrounding phones and the intonation (pitch, duration, and energy) which comes from the overall sentence structure, word emphasis, phrasing, sentence type and more. In order to generate speech using TTS, the speech signal has to be analyzed to extract acoustic features and annotated to describe what is being said.
Figure 1 shows an example of a recorded speech signal. The top pane shows the waveform which is a representation of the speech signal in the time domain. The middle pane shows the spectrogram in grayscale, which represents the speech signal in the frequency domain as a function of time. As a speaker varies their vocal tract to produce different sounds, the air coming from the lungs is modulated and causes some frequencies to be amplified more than others. The black areas in the spectrogram are regions where the amplitude is higher. Where you can see lines, they are called formants, and they occur in voiced sounds, mostly vowels. Different vowels have different formant movements, but they are also heavily influenced by coarticulation.
The bottom two panes are linguistic annotations for the words in the sentence and the phoneme symbols. Usually the text of the recording is processed to create a phonetic transcription and then an automatic aligner is used to determine where in the speech signal the phones start and end. The durations of phones depend on many factors including the type of phone, the surrounding phones, whether it occurs in a stressed syllable, whether the word is emphasized, where in the sentence it is located, etc. Some TTS systems automatically learn the alignment between input symbols and output acoustic features using an attention mechanism whereas other systems use a duration model that is trained with time-aligned input symbols.
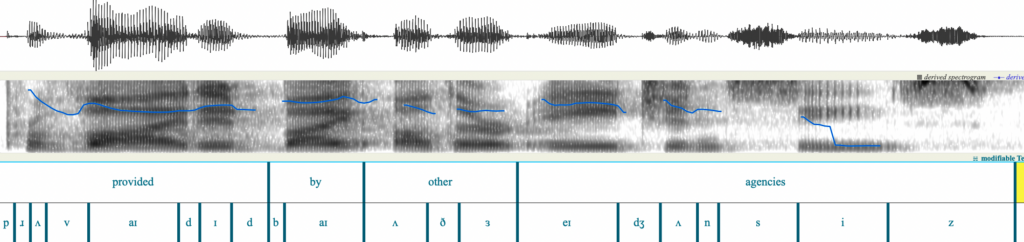
Figure 1: Speech waveform with annotations
System architecture
There are some TTS systems, called end-to-end or E2E systems, that treat the task of synthesizing text to speech as one single process. But most systems employ two or three distinct processes:
– Linguistic Component
– Acoustic model
– Neural vocoder

Figure 2: TTS architecture comprising of three modules
Linguistic component
The linguistic component analyzes the input text and segments it into sentences, normalizes the text by expanding abbreviations and translating numbers (including currencies, dates, etc) into words, and looking up or predicting pronunciations.
Typically, the acoustic feature prediction model is less complex and converges quicker if the input characters are phonemes instead of text, especially for languages where the relationship between text and pronunciations is not always straightforward. For instance in English you can have words such as ‘through’, ‘though’, and ‘tough’ which all end in the same four characters ‘ough’, but the pronunciation is different for all three of these words (‘through’ rhymes with ‘two’, ‘though’ rhymes with ‘low’, and ‘tough’ rhymes with ‘cuff’).
Some systems further translate the phoneme symbols to a set of binary articulatory features which describe different aspects of the phones such as whether it is a consonant or vowel, whether the consonant is voiced or unvoiced, rounded or unrounded, what type of consonant it is, and more. The advantage of using articulatory features is especially evident in multilingual or cross-lingual synthesis because different languages may have different phoneme symbols in their set and the overlap in articulatory features is greater than the overlap in phoneme symbols. It allows the system to converge faster with less training data.
Acoustic model
The acoustic model is a neural network model that learns a mapping between input symbols (text, phonemes, or articulatory features) and acoustic features that describe the speech signal at the frame level. The acoustic features are extracted from a speech database which typically has been recorded using a professional speaker and professional recording equipment. Some models capture the acoustic features all together in Self-Supervised Learning (SSL) features where others separate different aspects using Mel frequency cepstral coefficients, pitch, energy, and phone durations. There is also great variation in the network architectures and some systems employ additional modules to be able to synthesize multiple languages, speakers, emotions, or speaking styles.
During training, the model is presented with many examples to try to minimize various cost functions which represent the difference between the ground truth features and the predicted features from the model. A model can be trained from scratch on a fair amount of data, or one can pretrain a model and then finetune it with a smaller dataset to adapt it to another language, speaker, emotion, or speaking style.
Vocoder
A vocoder is a model that learns the mapping between the acoustic features and the corresponding speech signal. For some vocoders, you can find pre-trained universal vocoder models which can be finetuned to your target voice. The vocoder model is language independent. However, the output quality is better if it is trained with speech from many speakers speaking multiple languages. And if the goal is to synthesize expressive speech, there should also be ample material with larger pitch variations.
0 Comments